🚀 New Features
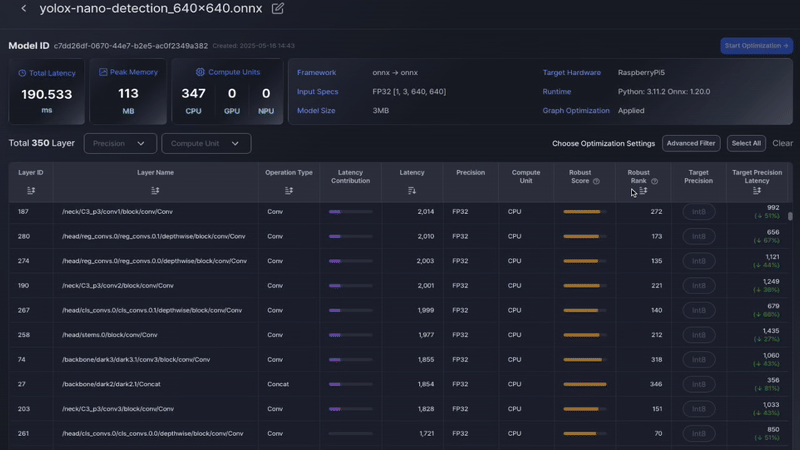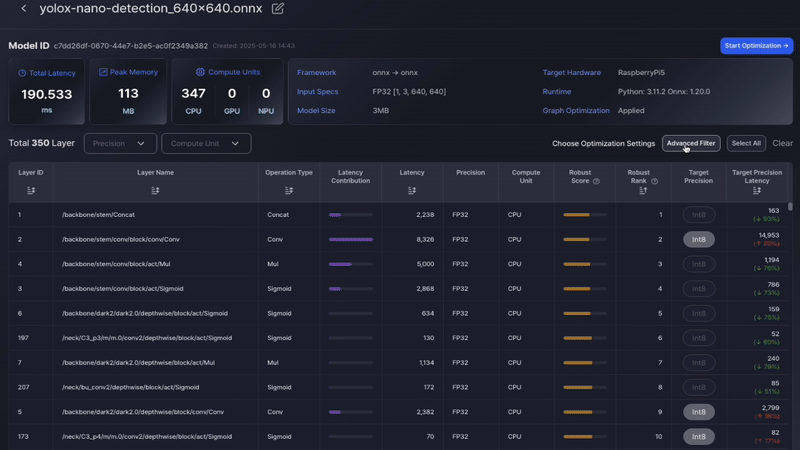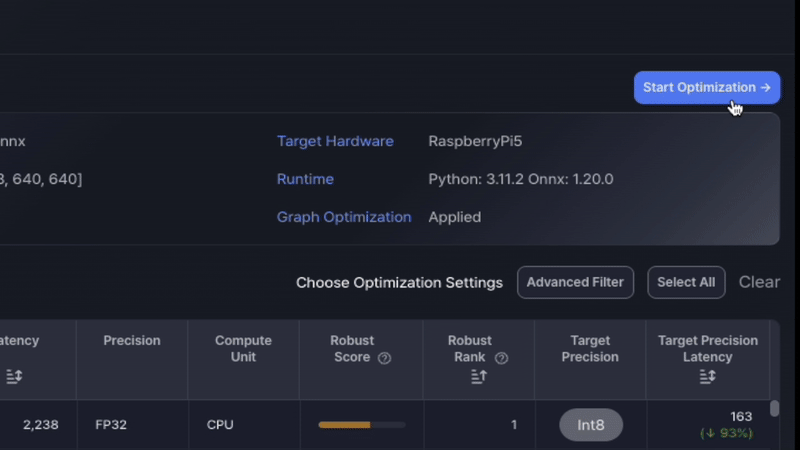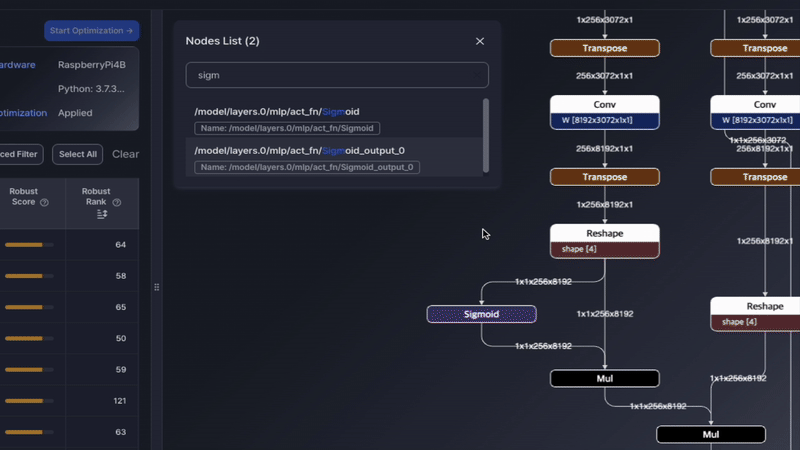
Minimap in Model Graph View A minimap has been added to the model graph view, allowing users to quickly navigate large models and maintain context while exploring detailed areas.
🛠️ Improvements
Updated Default Colors The default color scheme of the model graph has been updated for better readability.
Latency-Based Coloring Layers are now visually distinguished based on latency. Slower layers appear brighter, while faster layers appear darker, making performance bottlenecks easier to identify.
Enhanced Graph-Table Interaction Interactions between the graph view and table view have been improved, allowing seamless selection and navigation between the two representations.
🧠 Why These Matter
- Improved Navigation: The minimap helps users efficiently explore large and complex model graphs without losing context.
- Faster Bottleneck Identification: Latency-based coloring makes it easy to spot slow-performing layers at a glance.
- Seamless Analysis: Enhanced graph-table interaction allows for a smoother workflow between visual and tabular analysis, supporting more efficient profiling and decision-making.