
Features & Scope of support
NetsPresso Model Launcher (beta)
Accelerated models, simplified deployment
Key Feature
Quantization
- Quantization enables to run and accelerate an AI model on the target device.
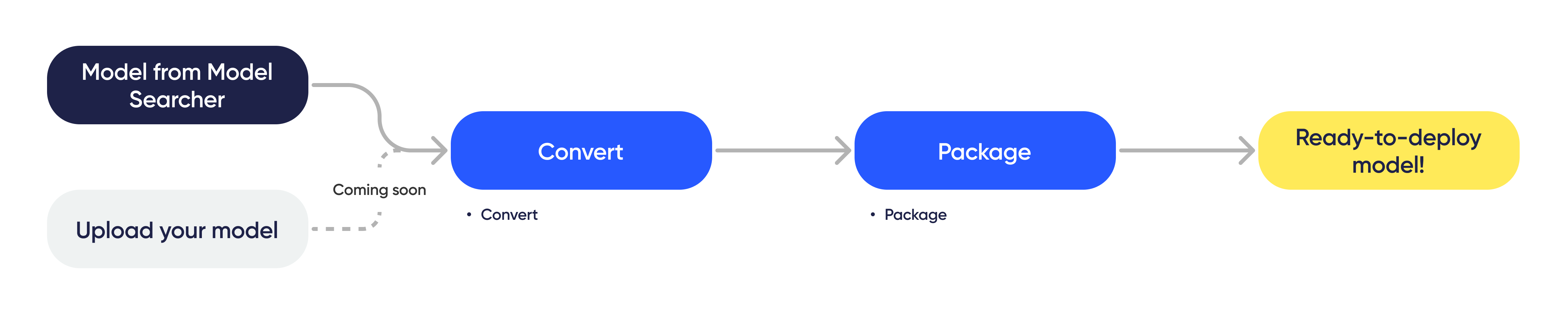
Convert and package
- Convert and compile AI models so that hardware can understand and run them.
- Package AI models with processing codes to be ready for the deployment
Device farm
- Actual hardwares are already installed in NetsPresso Device Farm to provide hardware-aware features.
Workflow
Scope of support
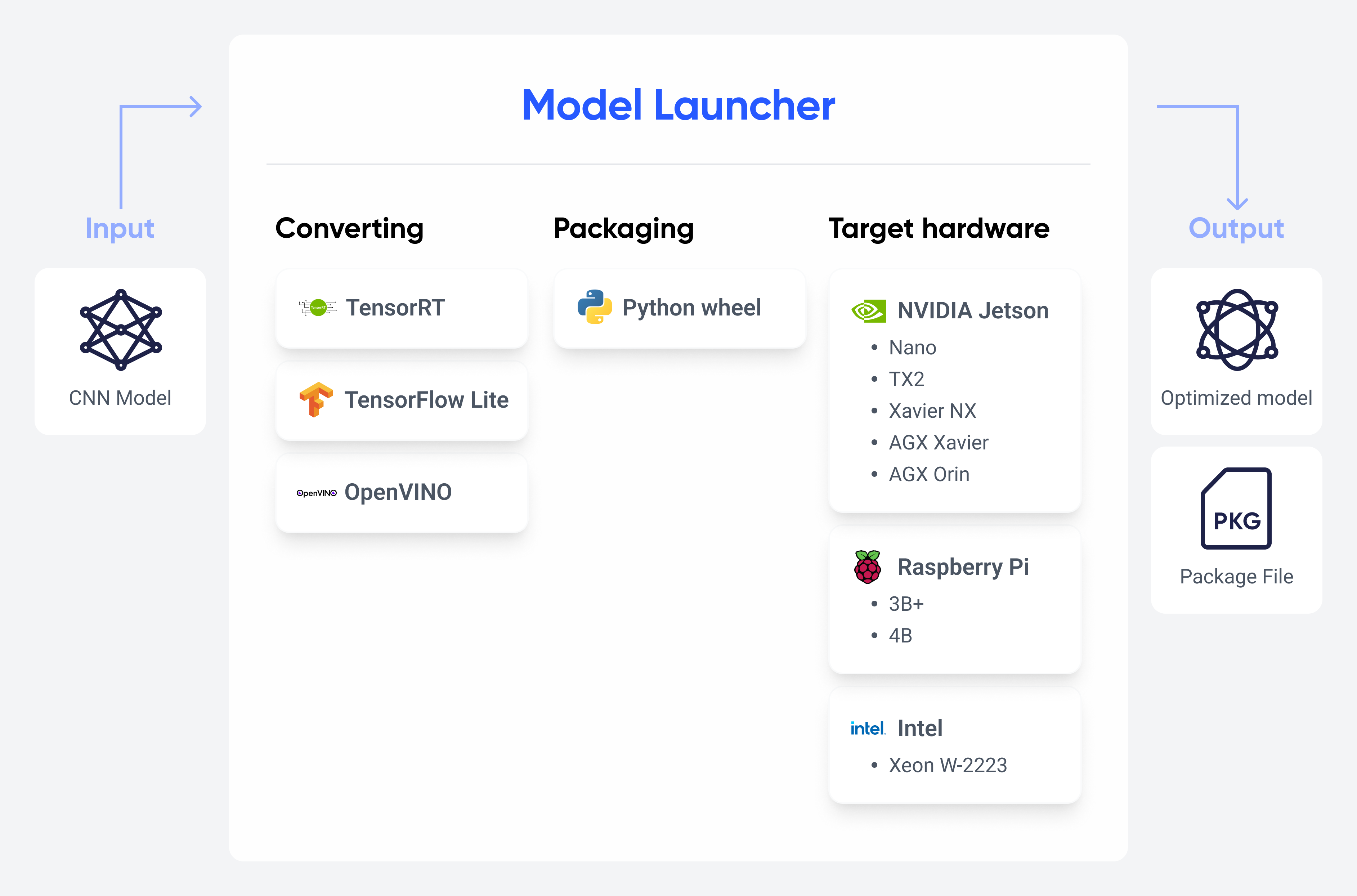
Converting options
- Models built with Model Searcher → TensorRT, TensorFlow Lite, OpenVINO
- ONNX → TensorRT, TensorFlow Lite, OpenVINO (Coming soon)
- TensorFlow → TensorFlow Lite (Coming soon)
Package formats
- Python wheel
- Packaging is available for models converted with Model Launcher
Hardware
- NVIDIA Jetson family (Nano, TX2, Xavier NX, AGX Xavier, AGX Orin)
- Raspberry Pi series (3B+, 4B)
- Intel Xeon W-2223
Updated 15 days ago