
What is NetsPresso?
NetsPresso: Hardware-Aware Optimization Platform
NetsPresso offers a comprehensive solution for optimizing AI models with full consideration of hardware specifications.
It automates the entire workflow — from training custom AI models, to optimizing them for specific devices, and benchmarking their performance on real hardware environments.
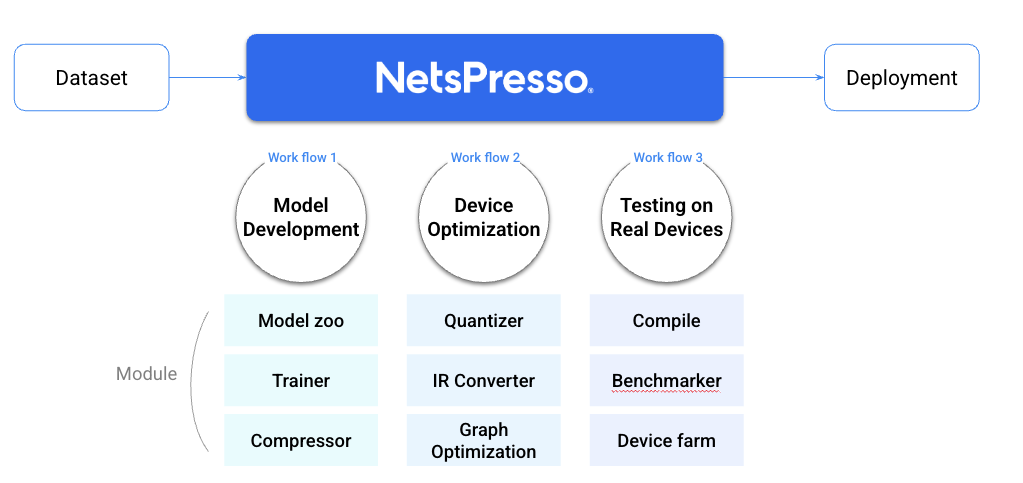
We divide the deployment process of AI models to edge devices into three key stages. Each stage has a distinct objective:
- Model Development: Build task-specific, lightweight models with high performance.
- Device Optimization: Maximize model performance for your target chip.
- Testing on Real Devices: Quickly and accurately validate performance on actual hardware.
NetsPresso consists of nine core engines, designed as modular components to easily connect with various workflows. Introduction to Core Engines
NetsPresso provides two interface options:
- A developer-friendly Python SDK for flexible integration. Learn how to use PyNetsPresso
- A visual GUI (NetsPresso Studio) that helps you intuitively understand each stage and gain insights into model optimization. Learn how to use NetsPresso Studio
Updated 11 months ago
What’s Next