
INT8 quantization with Benchmark Studio
What is Quantization?
Quantization is a technique that reduces the number of bits used to represent weights and activations in a deep learning model. This makes the model lighter, reducing memory usage and improving inference speed.
Optimization Studio facilitates the easy application of post-training INT8 quantization to the model. It represents the model's weights and activations as 8-bit integers, saving memory and accelerating computations.
This document provides information as follows:
- INT8 quantization with Benchmark Studio
- Preparing the calibration dataset
- Inference code for TFlite INT8 model
INT8 quantization with Benchmark Studio
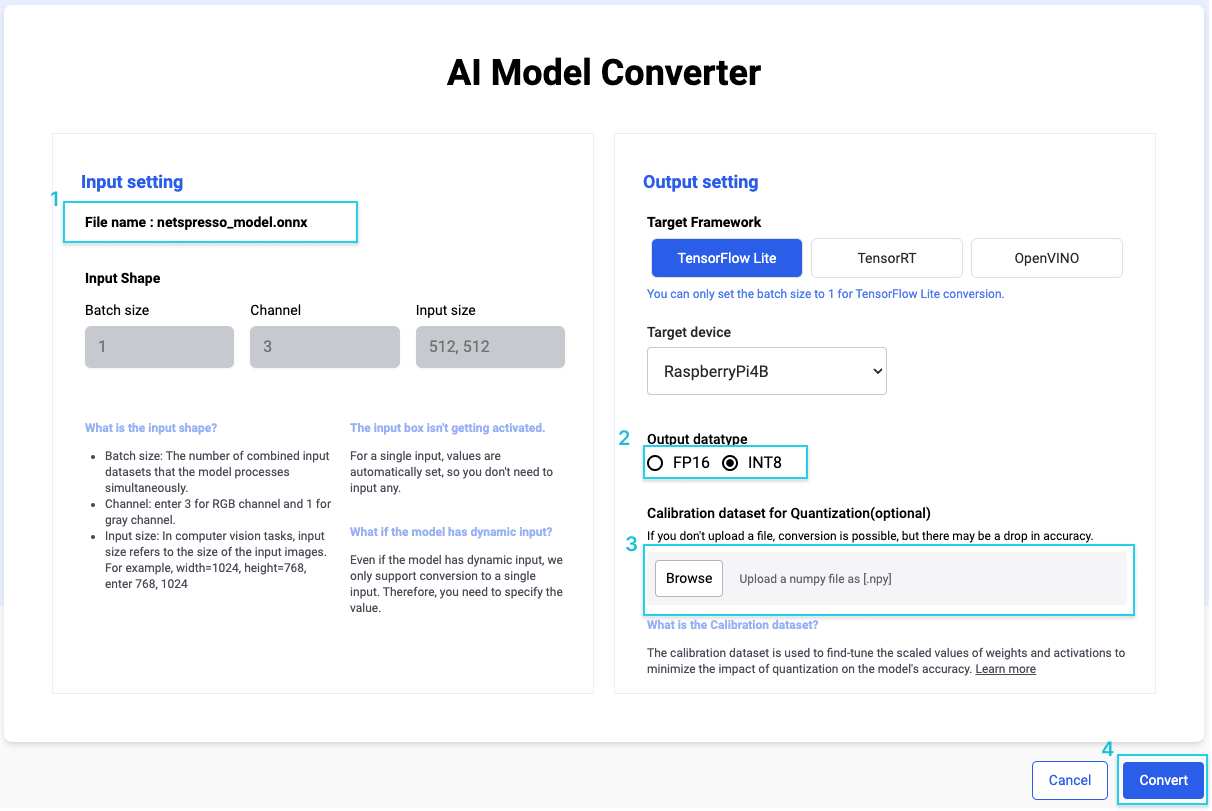
- To quantize, upload your target model or select from the free models in Models.
- On the Convert Setting page, choose Tensorflow Lite, select the target device, and then choose the INT8 option.
- Upload the calibration dataset(<= 500MB) to minimize quantization error.
- Click the convert button.
Preparing the calibration dataset
Calibration is the process of aligning a quantized model with a specific data distribution, adjusting quantization parameters such as scaling and zero points.
Generally, the calibration dataset is a subset of the original training data, used to fine-tune quantization parameters. Its purpose is to ensure the quantized model's optimal performance on real-world data while maintaining acceptable accuracy. During calibration, the model runs on this dataset, and activation statistics are collected. These statistics determine quantization parameters for each neural network layer, minimizing the impact of quantization on accuracy by adapting parameters based on observed value distributions.
Convert the dataset to NumPy for calibration.
- img_file_dir_path : Path where the dataset for calibration is stored.
- padding : Value for padding preprocessing.
- color_mode : Value to change the color mode of an image for preprocessing. Select ‘bgr’ or ‘rgb’.
- normalize : Value for normalization preprocessing.
- input_shape : Value for width and height of model input shape.
- save_file_path : Path to save the npy file.
from glob import glob
import os
import pathlib
import random
from typing import Literal, List, Tuple
import cv2
import numpy as np
img_file_types = [
"*.jpeg",
"*.JPEG",
"*.jpg",
"*.JPG",
"*.png",
"*.PNG",
"*.BMP",
"*.bmp",
"*.TIF",
"*.tif",
"*.TIFF",
"*.tiff",
"*.DNG",
"*.dng",
"*.WEBP",
"*.webp",
"*.mpo",
"*.MPO",
]
def save_npy_file(array, save_file_name: str):
np.save(save_file_name, array)
def print_saved_npy_file_shape(save_file_name: str):
array = np.load(save_file_name)
print(f"Saved npy array shape is {array.shape}")
def save_txt_file(lines: List[str], file_name: str):
with open(file_name, "w") as file:
for line in lines:
file.write(line + "\n")
file.close()
def print_error_files(error_files: List[str], file_name: str):
print(f"Please check files in {file_name}.")
print("Error files:", error_files)
def save_error_files(
error_files: List[str],
file_name: str = "error_files.txt"):
if len(error_files) != 0:
save_txt_file(error_files, file_name)
print_error_files(error_files, file_name)
class DataPreprocessor():
def __init__(
self,
root_dir: str,
input_shape: Tuple[int, int],
color_mode: Literal["bgr", "rgb"],
padding: bool,
normalize: bool
):
self.root_dir = root_dir
self.input_shape = input_shape
self.color_mode = color_mode
self.padding = padding
self.normalize = normalize
self.img_list = []
def _get_img_list(self,):
self.img_list = []
for root, dirs, files in os.walk(self.root_dir):
for img_type in img_file_types:
img_files = glob(os.path.join(root, img_type))
self.img_list += img_files
self.img_list = list(set(self.img_list))
if len(self.img_list) == 0:
raise Exception(f"No image in {self.root_dir}")
random.shuffle(self.img_list)
def _img_padding(self, im):
shape = im.shape[:2] # current shape [height, width]
new_shape = self.input_shape
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
# Compute padding
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
left, right = int(round((new_shape[1] - new_unpad[0])/2 - 0.1)), int(round((new_shape[1] - new_unpad[0])/2 + 0.1))
top, bottom = int(round((new_shape[0] - new_unpad[1])/2 - 0.1)), int(round((new_shape[0] - new_unpad[1])/2 + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114,114,114)) # add border
return im
def _preprocess(self, img):
x = []
if self.color_mode == "rgb":
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
if self.padding:
img = self._img_padding(img)
else:
img = cv2.resize(img, self.input_shape)
x.append(np.asarray(img))
x = np.array(x)
x = np.float32(x)
if self.normalize:
x = x / 255.0
return x
def _load_dataset(self,):
error_files = []
valid_images = []
def is_valid_image(image):
return image is not None
for f in self.img_list:
try:
img = self._preprocess(cv2.imread(f))
if is_valid_image(img):
valid_images.append(img)
else:
error_files.append(f)
except Exception as e:
error_files.append(f)
try:
result_array = np.concatenate(valid_images, axis=0)
except:
import pdb; pdb.set_trace()
return result_array, error_files
def _get_save_file_name(self,):
self._get_img_list()
count = len(self.img_list)
w = self.input_shape[0]
h = self.input_shape[1]
return f"{count}x{w}x{h}.npy"
def save_dataset_as_npy(self, save_file_path: str):
save_file_name = self._get_save_file_name()
save_file_path = os.path.join(save_file_path, save_file_name)
result_array, error_files = self._load_dataset()
save_npy_file(result_array, save_file_path)
print_saved_npy_file_shape(save_file_path)
save_error_files(error_files)
if __name__ == "__main__":
img_file_dir_path = "/image/file/path"
padding = True
color_mode = "bgr"
input_shape = (512, 512)
normalize = True
save_file_path = "/path/to/save/file"
data_preprocessor = DataPreprocessor(
img_file_dir_path,
input_shape,
color_mode,
padding,
normalize
)
data_preprocessor.save_dataset_as_npy(save_file_path)
Result
root@4e54bd5645d1:/app# python3 prepare_npy_file.py
Corrupt JPEG data: 122 extraneous bytes before marker 0xc4
Saved npy array shape is (145, 32, 32, 3)
Please check files in error_files.txt.
Error files: ['/app/calib_dataset/images/2007_000039_jpg']Dataset that failed to be read
Image files that do not open normally through opencv-python are listed in the 'error_files.txt' created in the code execution location.
Inference Code for TFlite INT8
Write and use additional pre-processing/post-processing codes for your model.
import os
import cv2
import numpy as np
import tensorflow as tf
def model_input_output_attributes(interpreter: tf.lite.Interpreter):
inputs = {}
outputs = {}
for input_detail in interpreter.get_input_details():
input_data_attribute = {}
input_data_attribute["name"] = input_detail.get("name")
input_data_attribute["location"] = input_detail.get("index")
input_data_attribute["shape"] = tuple(input_detail.get("shape"))
input_data_attribute["dtype"] = input_detail.get("dtype")
input_data_attribute["quantization"] = input_detail.get("quantization")
input_data_attribute["format"] = "nchw" if input_data_attribute["shape"][1] == 3 else "nhwc"
inputs[input_data_attribute["location"] if input_data_attribute["location"] is not None else input_data_attribute["name"]] = input_data_attribute
for output_detail in interpreter.get_output_details():
output_data_attribute = {}
output_data_attribute["name"] = output_detail.get("name")
output_data_attribute["location"] = output_detail.get("index")
output_data_attribute["shape"] = tuple(output_detail.get("shape"))
output_data_attribute["dtype"] = output_detail.get("dtype")
output_data_attribute["quantization"] = output_detail.get("quantization")
output_data_attribute["format"] = "nchw" if output_data_attribute["shape"][1] == 3 else "nhwc"
outputs[output_data_attribute["location"] if output_data_attribute["location"] is not None else output_data_attribute["name"]] = output_data_attribute
return inputs, outputs
def preprocess(input_image_path:str):
input_image = cv2.imread(input_image_path)
# Write down the pre-processing process required for your model, including resizing.
return input_image
def inference(tflite_model_path:str, input_image):
with open(os.path.join(tflite_model_path), "rb") as f:
interpreter = tf.lite.Interpreter(model_content=f.read(), num_threads=1)
interpreter.allocate_tensors()
inputs, outputs = model_input_output_attributes(interpreter)
for k, v in inputs.items():
if v['dtype'] in [np.uint8, np.int8]:
input_scale, input_zero_point = v["quantization"]
input_image = input_image / input_scale + input_zero_point
input_image = np.expand_dims(input_image, axis=0).astype(v["dtype"])
interpreter.set_tensor(v["location"], input_image)
interpreter.invoke()
output_dict = {}
for output_location in iter(outputs):
output_dict[output_location] = interpreter.get_tensor(output_location)
return output_dict
def postprocess(inference_results):
return inference_results
input_image=preprocess("your_image_file.jpg")
inference_result=inference("your_model.tflite", input_image)
postprocess(inference_result)Updated 11 months ago