
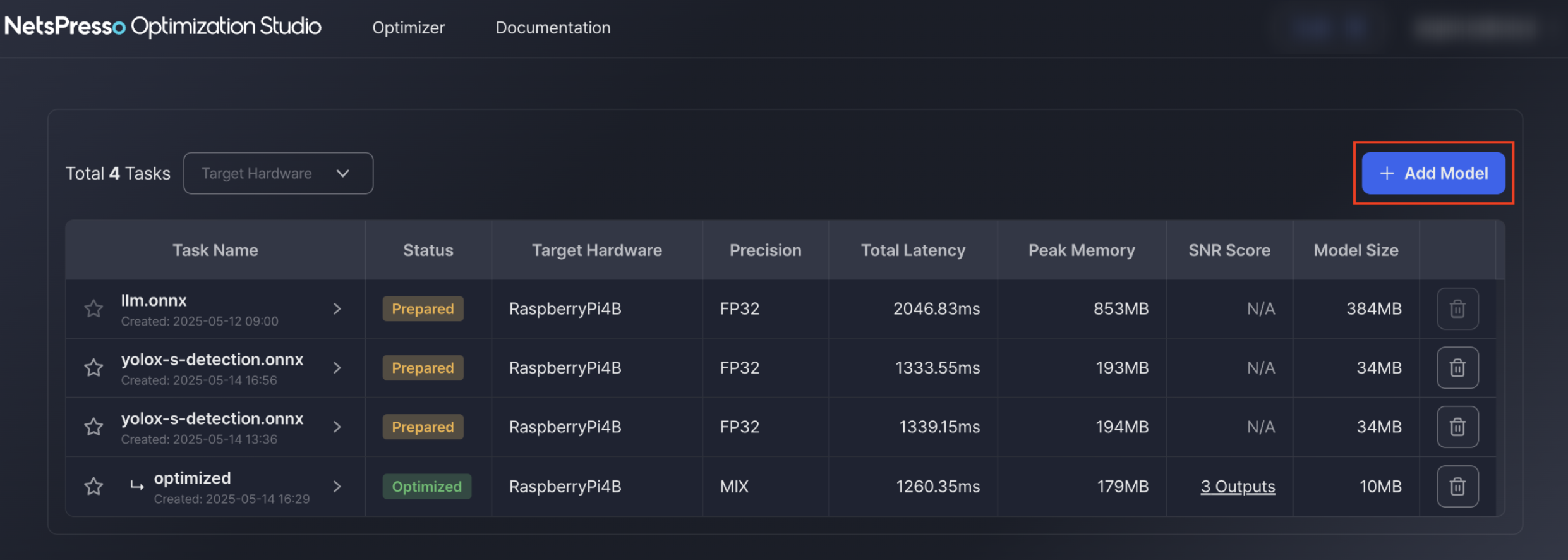
Step 1: Upload model
Step 1-1: Upload your model
- Upload ONNX format models.
- Models are stored and managed in your task list space.
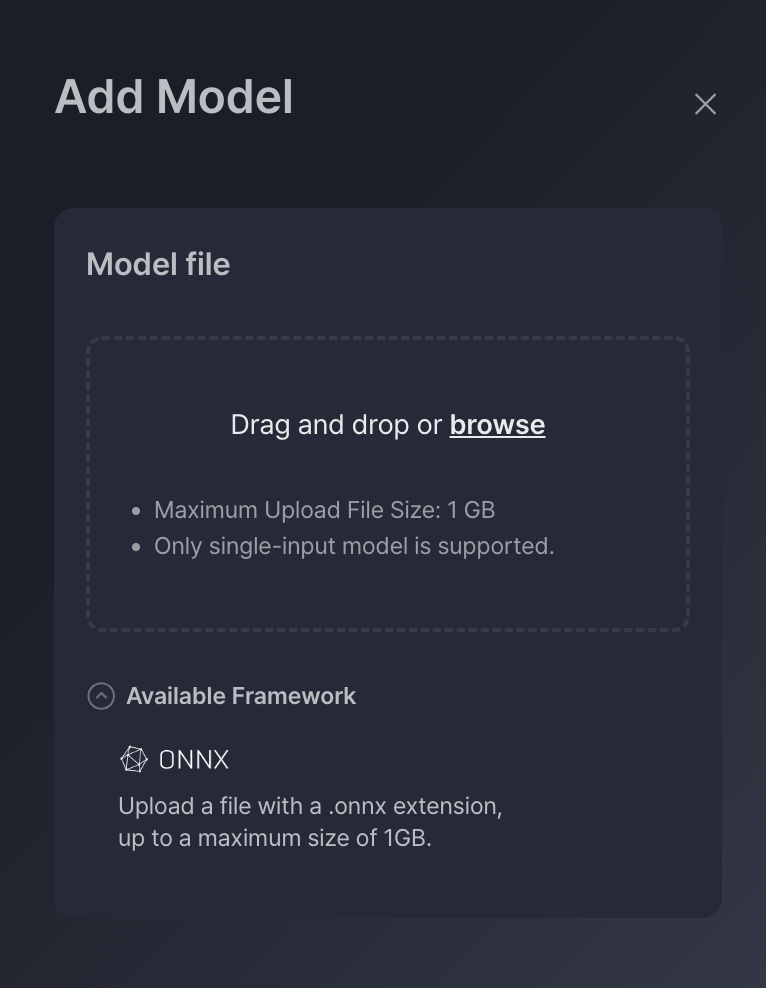
Input Requirements for Model Upload
up to 1GB
Single Input Only
The model must have exactly one input. Multi-input models are not currently supported.Shape Format: NCHW
The input tensor must follow the Channel-first format: Batch × Channel × Height × WidthFor example: 1 × 3 × 256 × 256
ONNX Model Requirement
Only models in ONNX format are supported for upload and optimization for now
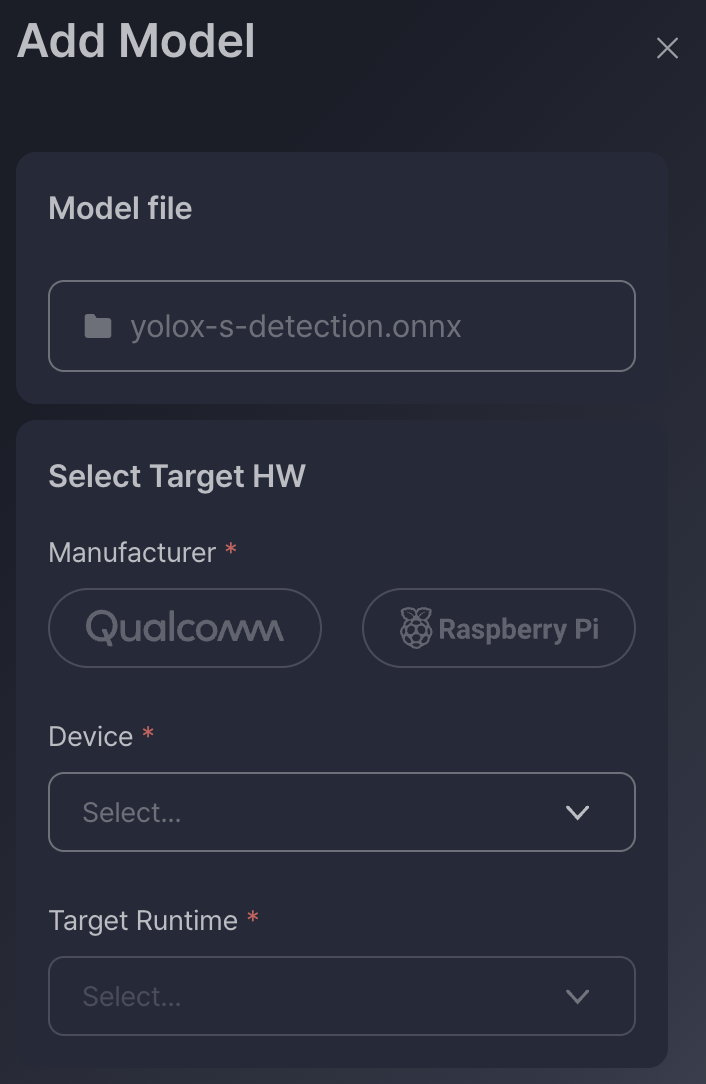
Step 1-2: Select target device
- Select device manufacturer (e.g., NXP, Renesas, NVIDIA)
- Select runtime (e.g., TensorFlow, ONNX Runtime)
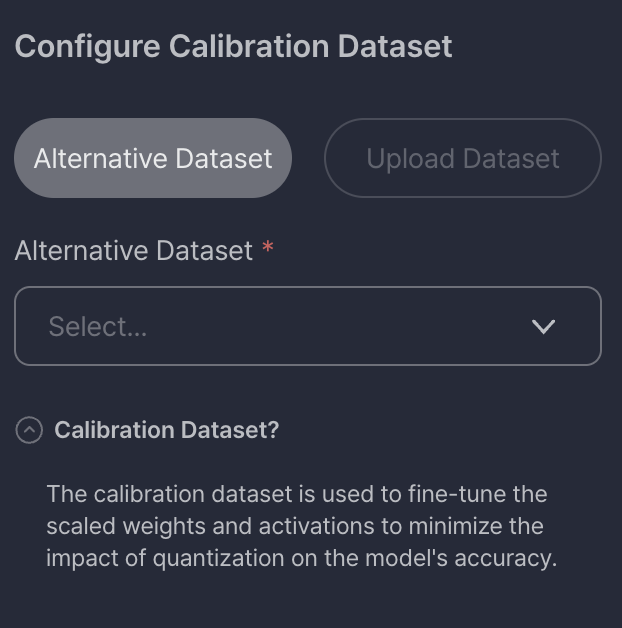
Step 1-3: Configure Calibration Dataset
Quantization can sometimes degrade model accuracy. To mitigate this, you can configure a calibration dataset — a small set of representative input data used to fine-tune the model's scaled weights and activations.
You have two options:
-
Alternative Dataset
- Select a pre-registered dataset to calibrate the model.
- The calibration dataset is used to fine-tune the scaled weights and activations to minimize the impact of quantization on the model’s accuracy.
-
Upload Dataset
- Upload your own dataset to improve calibration accuracy.
- To identify layers impacting model accuracy, a small dataset is required.
- The dataset must be in
.npyformat.
Learn how to prepare a calibration dataset here: Preparing the Calibration Dataset →
Step 1-4: Configure Graph Optimization
Enable or disable graph optimization to control how the computation graph is processed for your target hardware.
-
Enabled (default)
Graph optimization simplifies the model’s computation graph and replaces unsupported operations with device-compatible alternatives. This improves execution compatibility and performance across different hardware runtimes. -
Disabled
Skip optimization if you want to preserve the model structure exactly as-is. Note that this may lead to runtime compatibility issues or reduced performance.

Once the AI model is uploaded, it will appear in the Task List.
The Status column will show “Profiling”, which indicates a preprocessing step required before running optimization.

Task Status by Execution Stage
- Profiling: The added model is currently being profiled on the target device. Detailed information is not available until the job is complete.
- Prepared: Profiling has been completed. You can now view the model details and proceed with quantization.
- Optimizing: A new sub-task has been created under the original model, and quantization is in progress.
- Optimized: Quantization of the sub-model has been successfully completed.
- Failed: An error occurred during profiling or quantization, and the job was halted.
Updated 8 months ago